










Linux kernel: просто снять снапшот не просто
Содержание
- А что у других?
- Снапшоты в Linux
- DM cнапшоты LVM томов
- Альтернативы DM снапшотам
- Альтернатив больше нет?
- Немного хака с X86_CR0_WP
- Проблемы блочного уровня ядра Linux
- Моё видение решения проблемы
- Вместо заключения

Привет. Сегодня я бы хотел рассказать про проблему снятия снапшота для бэкапа, про свежее ядро Linux, и что мы на нём потеряли. Так что если вы используете Linux и делаете резервные копии — вам просто необходимо это знать. В противном случае вы можете оказаться без резервных копий.
Если кто не в курсе, то Veeam Software предлагает средства для резервного копирования. Список платформ и решений довольно внушительный, но я не об этом. Когда наша команда взялась за проект Veeam Agent for Linux (а в первой версии он назывался Linux Endpoint), то первый вопрос, который мы поставили перед собой: «Как снять снапшот?». И пришлось поресёрчить… А почему? Потому что open source. В Linux нет одного хорошего решения какой-то проблемы. Есть несколько, и все со своими «граблями». Но давайте по порядку.
А что у других?
Для начала рассмотрим кратко, как подобная проблема решается в других — а значит, проприетарных системах.
В самой популярной из систем есть для решения этой задачи целый сервис Volume Shadow Copy Service, он же VSS. Возможно, я бы поискал для этой задачи другое решение, но другого нет, а VSS есть и работает «из коробки». VSS снапшоты работают довольно интересно. В нашем блоге есть ознакомительная статья на эту тему. Из приятного: поддерживается взаимодействие с приложениями через VSS-Writers. VSS-Writers — это такой механизм, который позволяет предупредить, к примеру, движок базы данных: «Товьсь! Снимаем снапшот! Всем сбросить буфера и держаться за поручни!». Кроме того, так называемая «diff area», куда сбрасываются блоки, перезаписанные на оригинальном томе и которая может располагаться на любом томе с NTFS, в том числе и на том, с которого снимаем снапшот.
Отдельная прелесть — документация. Как её ругает один мой коллега — у меня уши в трубочку сворачиваются. Почти каждый день он её читает, и ругает, и что-то для себя находит. Не всегда, правда… На этот случай у него есть дизассемблер и дебагер, а я купил беруши.
В другой довольно популярной OS от одной «фруктовой» компании есть Time Machine. Другой мой коллега, который как раз разбирался со снапшотами, которые использует Time Machine, не ругался на документацию. Он хоть и более сдержан, но дело не в этом. Сложно ругаться на то, чего нет. Именно поэтому ссылка на википедию, а не на официальный сайт. Ресёрч на тему того, как с этим добром работать, удовольствия никакого не приносит, разве что вы мазохист. Но снапшоты на файловой системе APFS есть и довольно неплохо работают. Причём работают именно через APFS и никак иначе. Хотя, кажется, у HFS+ был свой механизм, но мы его не поддерживаем, ибо deprecated.
В нашей копилке есть и решение и для Unix. Кто-то cпросит: «Чта? Оно разве не засохло и отвалилось, когда появился Linux?». Отвечаю: «Да, засыхает, но пока не отвалилось.» Старые солярки тоже бэкапятся. Но тут всё выглядит так, как будто зализанный гоночный авто тащит на прицепе повидавший многое на своём веку Ролс-Ройс. Снапшотов нет. Только файловый бэкап, и, как следствие — минимум фичей. Едет, и слава богу.
Нельзя обойти стороной и гипервизоры. vSphere и Hyper-V молодцы. Можно снять снапшот с виртуальной машины. Можно получить change-tracking, то есть узнать заранее, какие блоки на дисках машины действительно изменились, а какие можно и не читать. KVM, кстати, тоже планируем поддержать в ближайшее время. Поддержка снапшотов там есть.
Снапшоты в Linux
Но вернёмся к нашим… в open source. Что тут есть из штатных средств? Есть LVM и BTRFS. Тут я слышу крики: «Даёшь ZFS!». Но замечу, что его нет в upstream ядра (пока). Хотя в Ubuntu 21.04 ZFS уже появился в диалоге при установке системы. Теперь сходу можно развернуть на ZFS рутовую систему, если, конечно не полениться нажать на кнопочку «Advanced features. ».
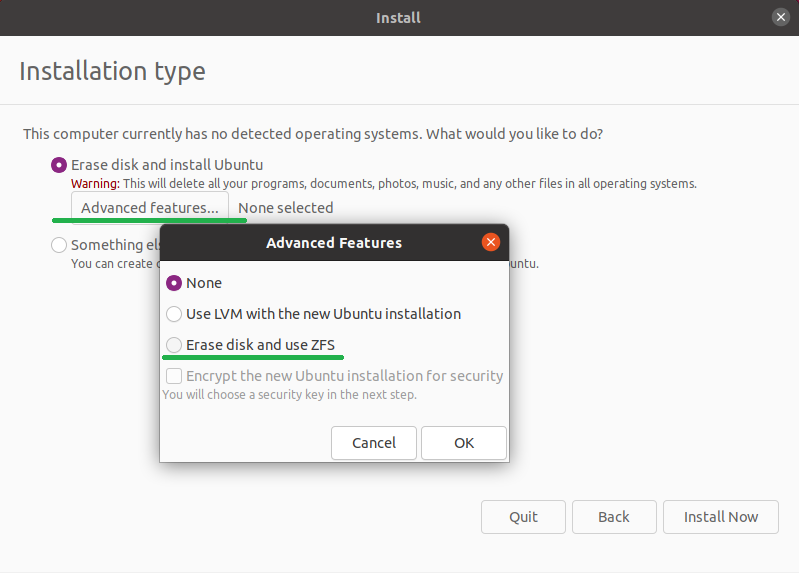
Тем не менее пока мы его не рассматриваем как штатное средство.
BTRFS мы поддержали в версии Veeam Agent for Linux версии 3.0. Основные претензии к ней — производительность. Больно уж много ресурсов требует бэкап при скорости из категории «так себе». Связано это с тем, что выполняется не просто копирование блоков, а синхронизация сорсной структуры файловой системы с таргетной. Получается что-то среднее между файловым и волюмным бэкапом. В общем, странное решение, кому интересно — читайте статью, там всё подробно описано.
Для быстрого и полного бэкапа в стиле «entire machine» лучше всего подходит именно снапшот всего блочного устройства, который как раз и реализован для томов LVM. Поэтому на нём я и остановлюсь подробнее.

DM cнапшоты LVM томов
В upstream ядра в сооставе DM есть модуль dm-snap, который позволяет создавать снапшоты блочных устройств. Звучит многообещающе, но рассмотрим, как с ним работать.

Итак, для начала разберёмся с понятиями. Есть Logical Volume Manager, он же LVM, а есть Device Mapper, он же DM. Не путайте DM и LVM — это разные понятия, но тесно связанные :).
LVM — это user-space средство для работы со специальными метаданными на диске. В этих метаданных указано, какие логические тома есть на диске и как их собрать. Поэтому он и Manager, так как в системе есть сервис, который эти метаданные читает и парсит. А вот сами логические тома в виде блочных устройств создаёт DM, реализованный в виде дополнительного модуля ядра dm-mod и подключаемых к нему подмодулей, таких, как dm-linear, dm-raid456, dm-snap. При этом основной код для работы с DM модулями ядра реализован в проекте lvm2. Итого, Logical Volume Manager управляет логическими томами, а на уровне ядра его поддерживает DM.
Открываем документацию на модуль ядра dm-snap, читаем:
Итак, вроде всё просто, давайте подставим вместо «volumeGroup» и «base» реальные значения и запустим этот код на вашей Linux машине и…
Fail #1 — у вас в системе диски не размечены под LVM.
При установке системы вы решили, что ни программные рейды, ни тонкие тома вам не нужны, и вообще лишние прослойки для вашего SSD будут только обузой. А что с этим можно поделать? Может, взять и смигрировать на LVM? Нельзя просто так взять и добавить LVM метаданные на диск.
Это боль. Проще по новой раскатать всю систему и перетащить данные, а это timeoff, причём надолго. А если вы админ и у вас под сотню серверов, да ещё и доставшихся вам по наследству от предшественника, который давно уволился, попутно утащив с собой сакральные знания, как это работало… Ну что ж — значит, снапшоты не для вас.
Но, допустим, вы — бывалый админ, на работе всегда ходите в красной шляпе, а дома исключительно в фетровой. Тогда вы ещё при установке вашей системы примените конфигурацию диска, которую вам советует установщик по умолчанию. Тогда у вас есть и Volume group, и на них есть тома. Подставляем значения в команду lvcreate и…
Fail #2 — у вас нет свободного места в volume group.
Свежераскатанная система, куча свободного места на файловой системе, а снапшот снять нельзя. Обидно, «из коробки не работает».
Что тут можно сделать? Берём в руки рашпиль, то есть bash-пиль, и дорабатываем это. Можно подключить ещё один диск, добавить его в volume group, или можно сделать ресайз файловой системы, ресайз логического тома… Ой, у вас 100 машин, и менеждер по безопасности с главой IT отдела смотрит на вас — менеджера по бэкапам — квадратными глазами и говорят, что ваш предшественник как раз и был уволен после того, как предложил подобный план, а в 4 часа ночи у него что-то не срослось на сервере бухгалерии и был offtime до самого обеда.
Но что-то я сгущаю краски. Вы опытный админ и носите балаклаву, под которой расположилась шапочка из фольги. И поэтому у вас в парке сотни машин и к каждной подключён сторедж в пару-тройку десятков терабайт. И на них базы, большие такие… И вот вы в ресторане в VIP зале со своим другом, тоже админом, попиваете дорогой коньяк. Балаклаву вы сняли, и макушка поблёскивает металлом. Только тут можно поделиться с другом, что инфраструктура ваша трещит по швам от перегрузок, причём именно ночью, когда весь ваш зоопарк нужно забэкапить. И каждую ночь ваше средство для бэкапа перечитывает ваш диск целиком, хотя изменений в нём около 2-3%. На что друг, почёсывая макушку под блестящей шапочкой, признаётся, что давно перевёл всё на виртуальную инфраструктуру, что позволяет зачитывать только инкремент, потому что гипервизор поддерживает change-tracking.
Fail #3 — просто снапшота уже давно недостатчно. Нужен change-tracking.
Объёмы данных растут, накопители тоже. Перезачитывать весь снапшот — недопустимое расточительство. Что тут можно сделать? Я слышал про dm-era. Вроде как он позволяет получить битмапину изменений. Но для меня пока загадка, как оно дружит с dm-snap и как нужно собрать стек dm устройств, чтобы оно стабильно работало. Полагаю, должен быть пирог типа:

Если кто в теме, или есть рабочая конфигурация — дайте знать. Мне очень интересно. Особенно интересно оценить перфоманс такого решения. Тут дело в том, что DM при перехвате создаёт новое bio, копирует в него флаги и указатели на страницы в памяти, в которые нужно прочитать или из которых данные нужно записать. А при завершении bio от DM вызывается и callback для завершения исходного bio. То есть при таком вот пироге мы получим дополнительные 3 выделения памяти с последующим перекладыванием байтиков из структурки в стурктурку.
А в свете новых тенденций, когда ПЗУ на микросхемах работает на невероятных скоростях и бутылочным горлышком становится не железка, а операционная система, подобный оверхед мне кажется неприемлемым.
Альтернативы DM снапшотам
Ну конечно, не всё так печально, как я описал, и есть альтернативы. Когда мы ресёрчили вопрос со снапшотами для нашего Veeam Agent for Linux, мы посмотрели, как с этим справляются другие. Оказалось что многие ограничиваются файловым бэкапом. Более серьёзные вендоры предлагают использовать специальный модуль ядра, который реализует логику фильтра блочного устройства. Есть модули проприетарные, но есть и с GPL лицензией. Суть работы тех, что я видел, одинакова: выполняется перехват функции make_request_fn из структуры request_queue. А на тему того, как реализовать фильтр блочного устройства, даже статьи были типа этой.
Собственно наше решение было очевидным, был создан собственный модуль veeamsnap, об его устройстве даже статься на Хабре была. Проблема с таким модулем одна — он не в upstream, значит с каждым релизом ядра, модуль может перестать работать. За несколько лет модуль оброс довольно солидным набором директив условной компиляции, но успешно работал на ядрах от 2.6.32 до 5.8. Вопрос совместимости был поставлен на поток. Наш QA проверяет совместимость модуля с каждым релизом ванильного ядра.
Альтернатив больше нет?
Как-то прошлым летом приходит весточка из QA, что снова что-то сломалось. Я уже было приготовился сделать очередной маленький фикс для ядра 5.8, но оказалось, что ключевая функция make_request_fn() может оказаться не определена. То есть перехватывать её по старинке уже не выйдет. А заглянув в 5.9, я увидел, что она была перенесена из request_queue в gendisk и переименована. При этом трюк с перехватом более не сработает, так как теперь она const.
Выдохнув, остыв и подумав, я попробовал написать автору изменений с вопросом, а как теперь перехватывать запросы к block layer и вообще строить фильры блочного уровня. Ответ цитирую:
И да, нужно признать, что это чистая правда. Действительно модули ядра для перехвата запросов к блочным устройствам никогда не поддерживались. И в upstream не было таких модулей, которым перехват этой функции был бы нужен. На моё предложение реализовать какое-то альтернативное решение я ответа не получил.
Итог: альтернатив DM снапшотам больше нет. Ну, почти нет.
Немного хака с X86_CR0_WP
На самом деле, если в регистре CR0 для x86_64 архитектуры поправить 16-тый битик (WP), то можно будет перезаписать и константные значения. В принципе, это открывает широкие возможности для перехвата всего, чего угодно. Наверное, поэтому в штатной функции обращения к регистру native_write_cr0() реализована защита от «случайного» выключения этого бита.
Тем не менее, если упростить штатную функцию буквально до одной строки:
то перехват снова может быть реализован.
Да, мне не нравится такое решение. Да, это выглядит как rootkit. Да, майнтейнеры не одобрят. Однако это решение работает, а для out-of-tree модуля ядра не остаётся другого выбора.
Проблемы блочного уровня ядра Linux
Итак, попробую подвести итог описательной части и сфомулировать проблему более точно. А их на самом деле две.
- Отсутствует возможность реализовать модуль-фильтр блочного устройства.
- В составе штатных средств ядра Linux нет способа снять снапшот с любого блочного устройства.
На мой взгляд, решать эту проблему просто экономически невыгодно. Дело в том, что изначально вендоры средств резервного копирования ориентированы на enterprise сегмент и платный софт. Зарабатывать на Linux всегда было сложно, и объём рынка не так велик. В общем, поддержка Linux выполнялась по остаточному принципу. При таком раскладе тратить значительные силы на предложение своего решения в upstream было нецелесообразно бизнесу (пока всё работало на out-of-tree модулях).
А если кто не в курсе, ситуация с ядром Linux такова: либо ты предлагаешь свои решения и участвуешь в разработке ядра, либо ты плывёшь по течению и пользуешься тем, что есть. И если ты не предложил хорошую платформу для работы своего решения, то обращаться с просьбой «сделать хорошо» просто не к кому.
Дистрибутеры, которые предлагают решения на базе Linux, тоже хотят заработать. Наверное, на платных курсах от Red Hat можно узнать, как правильно развернуть систему, чтобы обеспечить возможность резервного копирования. А сертифицированный специалист поможет сделать это для бизнеса. Опять же, нужно создавать условия, когда платная поддержка необходима.
Возможно, истинная причина ускользает от моего взгляда. Дайте знать в комментариях.
Моё видение решения проблемы
Я, как большой любитель Linux и сторонник open-source, решил, что настало время исправить ситуацию. Раз есть чёткое понимание проблемы, значит, есть отличный шанс попробовать её решить! Пришлось искать пути решения и предлагать их в upstream. Даже статью сделал, вступив на этот тернистый путь. В целом не могу назвать тут. Ветка на базе ядра 5.12 здесь. Для 5.13 тоже есть ветка. На мой взгляд, решение уже выглядит работоспособным. По крайней мере, первый срез багов был зачинен. Оценка перфоманса с помощью perf показала, что издержки на фильтрацию незначительны. В ближайшее время я планирую заняться комплексным тестированием своего решения. Ну а потом буду предлагать в upstream.
Вместо заключения
Мне интересен feedback от вас, дорогие читатели и любители Linux. Может, кто-то даст дельный совет, может, кто-то озвучит свою идею. Может, кто-то сделает ревью и найдёт баг или архитектурную проблему. В идеале было бы здорово собрать группу единомышленников, которые бы были заинтересованы в решении обозначенных проблем. В этом случае шансы их решить значительно увеличатся.
А если у вас есть полезная и достаточно интересная, что немаловажно, идея для фильтра блочного устройства — пишите в комментах, пишите в личку. Может, объединив усилия, мы сможем предложить действительно нужный и полезный фильтр-модуль и API для его работы для upstream.
Возможно, проблемы на самом деле нет, а я просто не вижу очевидных решений, тогда просветите меня, пожалуйста. Я знаю, что могу ошибаться, потому что регулярно чиню свои баги.
Только не надо холиварить на тему «ZFS спасёт мир» или что какая-то ОС или дистрибутив лучше другой. Комментарии на тему «А я вот логи базы экспортирую и с помощью rsync тащу файлики» тоже не интересны, так как я рассматриваю резервную копию всей системы целиком, а не какую-то её часть.
So, feedback is welcome!
З.Ы. Тут охотники за головами прискакали на своих каблучках, тычут бумажкой с надписью «WANTED».

Там «все работы хороши — выбирай себе не вкус» — как писал классик (классик — это Маяковский, а не Пушной :).
Источник: