










Data Vault. Серия 1: Знакомство с Data Vault
Содержание
- 2.0 Определение Data Vault
- 3.0 Компоненты Data Vault
- 4.0 Решение архитектурных недостатков хранилищ данных
- 5.0 Основы архитектуры Data Vault
- 6.0 Возможные применения Data Vault
Назначение этого документа представить и обсудить заявленную на патент технологию под названием Data Vault ™ (прим. переводчика: статья была написана в 2001 году, в предоставлении патента было отказано в январе 2005; сейчас архитектура Data Vault общедоступна FREE and PUBLIC DOMAIN). Data Vault™ новый этап эволюции моделирования данных для хранилищ данных масштаба предприятия. Этот, сугубо технический документ, предназначен для аудитории, состоящей из проектировщиков данных, архитекторов данных и администраторов баз данных. Документ не предназначен для бизнес-аналитиков, менеджеров проектов и программистов. Рекомендуется, чтобы читатель обладал базовым уровнем знаний в области моделирования данных и хорошо понимал термины: таблицы, отношения, родитель, потомок, ключ (первичный / внешний), измерения и факты. Предметы обсуждения этой статьи следующие:
- Определение Data Vault.
- Краткая история моделирования данных для хранилищ.
- Архитектурные проблемы существующих моделей хранилищ данных.
- Важность архитектуры и дизайна для корпоративных хранилищ данных.
- Компоненты Data Vault.
- Решение существующих проблем архитектуры хранилищ данных.
- Основы архитектуры Data Vault.
- Возможные применения Data Vault.
Прочитав это документ, Вы можете узнать:
- Что такое Data Vault и какое она имеет значение.
- Как самому создать небольшое хранилище Data Vault.
- Какие перспективы хранилищ данных несостоятельны.
Слишком долго мы ждали структур данных, которые, наконец-то, приблизятся к приложениям искусственного интеллекта и приложениям интеллектуального анализа данных (data mining ). Большинство технологий интеллектуального анализа данных (data mining) требуют импортировать информацию в плоские файлы, чтобы соединить форму с функцией. К сожалению, объемы хранилищ данных растут быстро, и экспортировать эту информацию, предназначенную для интеллектуального поиска данных, становится все труднее. Просто не имеет смысла иметь эту неоднородность/разрыв между формой (структурой данных), функцией (искусственным интеллектом), и выполнением (осуществлением добычи данных).
Объединение формы, функции и выполнения имеет огромное значение для сообщества искусственного интеллекта (AI) и интеллектуального анализа данных. Найдена структура данных, которая математически обоснованно увеличивает возможность вернуть эти технологии к использованию баз данных, а не файлов. Модель Data Vault основана на математических принципах, которые позволяют ей быть расширяемой и способной к обработке огромных объемов информации. Эти архитектура и структура данных предназначены для обработки динамических меняющихся отношений между информацией.
Мы надеемся, что напряженное мышление в один прекрасный день инкапсулирует данные с функциями интеллектуального анализа данных, чтобы приблизиться к образцу обладающей самосознанием независимой информации, но это пока только мечта. Но можно динамически формировать, понижать, и оценивать отношения между наборами данных. Таким образом, изменяя ландшафт возможностей модели данных, по существу, мы приводим модель данных в динамически меняющееся состояние (благодаря использованию интеллектуального анализа данных / искусственного интеллекта).
Благодаря реализации эталонной архитектуры (reference architecture) поверх структуры Data Vault функции, имеющие доступ к контенту, могут начать выполняться в параллельном и автоматическом режиме. Data Vault решает часть структурных проблем Корпоративного Хранилища Данных и проблемы хранения, причем, используя нормализованный, лучший в своем роде, подход. Эти концепции предоставляют целый ряд возможностей применения этой уникальной технологии.
Вы должны стремиться делать то что, по Вашему мнению, Вы не сможете сделать,
Элеонора Рузвельт.
2.0 Определение Data Vault
Определение:
Data Vault набор уникально связанных нормализованных таблиц, содержащих детальные данные, отслеживающих историю изменений и предназначенных для поддержки одной или нескольких функциональных областей бизнеса.
Это — гибридный подход, обобщающий лучшие свойства третьей нормальной формы (3NF) и схемы Звезда (Star schema ).
Дизайн Data Vault гибок, масштабируем, последователен и приспосабливаем к потребностям предприятия. Это модель данных, спроектированная специально для удовлетворения потребностей хранилищ данных предприятия.
Архитектура Data Vault предназначена для удовлетворения потребностей хранилищ данных (data warehouse ), не путайте с витринами данных (data mart). Также может исполнять вторую роль Operational Data Store (ODS ), при условии применения для поддержки этого правильных аппаратных средств и ядра базы данных. Data Vault может обрабатывать большие наборы детальных данных используя меньшие физические объемы, по сравнению и с 3-ей нормальной формой (3NF), и по сравнению со схемой Звезда (Star schema). Data Vault имеет твердый фундамент, основанный на математических принципах, которые поддерживают нормализованные модели данных. В модели Data Vault содержаться структуры, которые знакомые и соответствуют традиционным определениям схемы звезда и 3NF, включая: измерения, связи многие ко многим и стандартные табличные структуры. Различия заключаются в представлении отношений, структурировании полей и хранении детальных данных, основанных на времени. Методы моделирования, встроенные в Data Vault, испытаны годами проектирования и тестирования в самых различных сценариях, а также твердым подходом к хранилищам данных.
2.1 Краткая история моделей для хранилищ данных
Подход 3NF третья нормальная форма был первоначально создан в начале 1960-ых (см. Эдгар Кодд (Edgar F. Codd) и Кристофер Дейт (Christopher J. Date)) для систем оперативной обработки транзакций (OLTP ). В начале 1980-ых это подход был приспособлен к возрастающим потребностям хранилищ данных. По существу, доработка заключалась в добавлении временной метки (date-time stamp) к первичным ключам каждой таблицы (см. иллюстрацию 1 ниже).
Со второй половине 1980-х в моделировании данных стали применять схему Звезда (Star schema). Эта схема была спроектирована, чтобы решить предметно-ориентированные проблемы, включая (но, не ограничиваясь): агрегирование , изменение структуры модели данных, производительность запросов, повторное или совместное использование информации, простоту использования, и способность поддерживать аналитическую обработку в реальном времени (OLAP ). Эта, сконцентрированная на едином предмете архитектура, стала известна как витрина данных (data mart). Вскоре схема Звезда также была приспособлена для мульти-предметных хранилищ данных, как попытка удовлетворить возрастающие потребности хранилищ данных предприятия, и получила название Согласованные витрины данных (Conformed Data Marts).
Рисунок 1. История моделей для хранилищ данных
Низкая производительность и другие слабости, как третьей нормальной формы (3NF), так и схемы Звезда, при использовании в хранилищах данных предприятия, начали проявлять себя в 90-ых, поскольку объемы данных увеличились. Модель Data Vault спроектирована, чтобы преодолеть эти недостатки, сохраняя сильные стороны архитектуры 3NF и архитектуры звезда. В течение прошлого года (от даты этой статьи, т.е. в 2001-02), эта техника была благосклонно принята индустриальными экспертами. Data Vault следующее шаг в эволюции моделирования данных, потому что это создавалось специально для корпоративных хранилищ данных.
2.2 Проблемы существующих архитектур и моделей данных для хранилищ данных
Все техники моделирования имеет ряд ограничений при их применении в архитектуре хранилищ данных масштаба предприятия. Это происходит из-за того, что используется адаптация, а не дизайн, первоначально созданный специально для этой задачи. Эти ограничения уменьшают удобство и простоту использования и постоянно являются поводом к священным войнам в мире хранилищ данных. Следующие строки касаются этих архитектур, применяемых не в их первоначальных целях, а для хранилищ данных.
Третья нормальная форма (3NF) имеет следующие осложняющие жизнь проблемы: проблемы первичного ключа, зависимого от времени и от сложных родительско-детских отношений; воздействие каскадных изменений; трудности загрузки в режиме близком к реальному времени; трудоемкие запросы; проблематичный drill-down анализ; проектирование сверху вниз и неизбежная нисходящая сверху вниз реализация (top-down). Следующий рисунок представляет собой оригинальную 3NF модель, приспособленную к архитектуре хранилища данных. Особенно острая проблема очевидна когда временная отметка (date-time stamp) помещается в первичный ключ родительской таблицы (см. рисунок 2). Это необходимо, чтобы отображать историю происходящих со временем изменений детальных данных.

Проблемой является масштабируемость и гибкость. Если добавить дополнительную родительскую таблицу, такое изменение вызовет каскадные изменения всех нижележащих подчиненных таблиц. Кроме того, если вставлена новая строка с существующим родительским ключом (единственное измененное поле временная отметка), то все дочерние строки должны быть повторно переназначены на новый родительский ключ. Этот каскадный эффект оказывает огромное влияние на процессы и модель данных, причем чем больше модель, тем больше воздействия. Это мешает (или делает невозможным) расширять и поддерживать модель данных масштаба предприятия. От этого в результате страдают архитектура и дизайн.
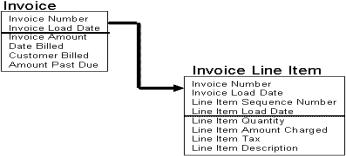
Рисунок 2. Временная отметка в 3NF
У согласованных витрин данных также есть проблемы. Согласованные витрины данных набор таблиц фактов, которые связаны через первичные / внешние ключи другими словами, набор нескольких взаимосвязанных схем Звезда. Это создает многочисленные проблемы: изолированная предметно ориентированная информация; возможная избыточность данных; несовместимые структуры запросов; проблемы масштабируемости; трудности со связыванием таблиц фактов (несовместимая степень детализации); проблемы синхронизации при загрузках близких к реальному времени; ограниченные представления корпоративной информации и неудобная среда для интеллектуального анализа данных (data mining). Хотя схема звезда, как правило, проектируется и реализуется снизу вверх (bottom up) по восходящей, однако согласованные витрины данных должны проектироваться сверху вниз, а реализовываться по восходящей снизу вверх. Однако, неофициальный опрос показал, что они фактически и проектируются, и реализуются снизу вверх.
Одной из самых трудных проблем согласованных витрин данных (или согласованных таблиц фактов) является получение правильной степени детализации. Это означает понимать, как данные агрегируются для каждой таблицы фактов, и гарантировать, что агрегирование останется согласованным всегда (все время жизни отношений), и структура каждой таблицы фактов не изменится, то есть, никакие новые измерения не будут добавлены ни к одной таблице фактов. Это ограничивает дизайн, масштабируемость и гибкость модели данных. Другая проблема вспомогательная таблица. Эта таблица предназначена, чтобы быть связью между взаимозависимыми измерениями. Степень детализации очень важна, так как это стабильность конструкции измерений. Это также ограничивает дизайн, масштабируемость и гибкость модели данных.
Рисунок 3. Согласованные витрины данных
Если степень детализации таблицы фактов Revenue (Доход) изменится, то это уже будет не та же самая таблица фактов. При добавлении измерения к одной из таблиц фактов степень детализации часто меняется. Предполагается также, чтобы таблицы фактов могут быть связаны друг с другом потому, что они содержат одни и те же ключи измерений. Это верно только в том случае, если факты агрегированы с одной и той же степенью детализации во всех таблицах, что чрезвычайно трудно поддерживать, так как система растет и развивается.
2.3 Важность архитектуры и дизайна для корпоративных хранилищ данных
Хранилище данных следует проектировать сверху вниз (top down) и реализовывать снизу вверх (bottom up). Это позволяет архитектуре достигать максимально известных границ знания, в то же время, позволяя реализации оставаться в контролируемых рамках, что все вместе может способствовать быстрым срокам поставки. Поэтому реализация должна быть проектированием набора plug-and-play таблиц, не становясь при этом узким местом сразу после поставки. Дизайн и архитектура хранилища данных должно быть достаточно гибким, чтобы расти и меняться с потребностями бизнеса, потому что потребности сегодняшнего дня не обязательно потребности завтрашнего дня.
Наша индустрия испытывает потребность в формализованной архитектуре моделирования данных и дизайне, которые способны к точному представлению хранилищ данных. Архитектура должна иметь нормализацию, определенную именно для хранилищ данных, а не для систем OLTP. Например, для OLTP определена нормализация 1-ой, 2-ой и третьей нормальных форм; а так же есть 4-ая, 5-ая и возможно 6-ая нормальные формы. У Хранилища данных сегодня нет таких структурированных или предопределенных форм нормализации для моделирования данных. Также очевидно, что уже не достаточно случайных усилий по нормализации архитектуры корпоративных хранилищ данных. Несогласованности методов моделирования приводят к напряженной реализации.
Data Vault определение нормализации моделей данных для хранилищ. Ее сила заключается в использовании определенной структуры, из которой строится модель. Data Vault использует некоторые из следующих методов моделирования данных: отношения многие ко многим, ссылочная целостность, минимально избыточный набор данных и информационные хабы с ключевыми бизнес-функциями. Эти методы делают модель данных Data Vault гибкой, расширяемой и согласованной. Подход к построению модели данных является итеративным, предоставляющим архитекторам данных и деловым пользователям платформу для построения хранилища данных на компонентной основе (см. статью Билла Инмона: Data Mart Does Not Equal Data Warehouse, DMReview.com).
3.0 Компоненты Data Vault
Для того чтобы сохранить дизайн простым и изящным, используется минимальное количество типов сущностей: Хаб (Hub), Связь (Link) и Спутник (Satellite). Дизайн Data Vault сосредоточен вокруг функциональных областей бизнеса представленных первичным ключом сущности Хаб (Hub). Сущность Связь (Link) обеспечивает транзакционную интеграцию между Хабами. Сущность Спутник (Satellite) предоставляет контекст первичного ключа Хаба. Каждый сущность предназначена для обеспечения максимальной гибкости и масштабируемости, сохраняя при этом большинство традиционных навыков моделирования данных.
3.1 Сущность Хаб (Hub)
Хабы (Hub), являются отдельными таблицами, содержащими как минимум уникальный список бизнес ключей. Эти ключи — то, что бизнес используют в повседневных операциях. Например, номер счета-фактуры, номер сотрудника, номер клиента, номер компонента и VIN (vehicle identification number — идентификационный номер транспортного средства). Если бизнес потеряет ключ, то они потеряют ссылку на контекст или окружающую информацию. Другие атрибуты Хаба включают:
- Суррогатный ключ (Surrogate Key) необязательный компонент, возможно смарт-ключ или порядковый номер.
- Временная отметка даты загрузки (Load Date Time Stamp), регистрирующая, когда ключ впервые был загружен в хранилище.
- Источник данных (Record Source) регистрация исходной системы, используется для обратной трассировки (отслеживания) данных.
Например, требования заключаются в том, чтобы собирать номера клиентов по всей компании. Бухгалтерия может иметь номер клиента, представленный в цифровом стиле (12345) а отдел контрактов может иметь тот же номер клиента с буквенной приставкой (AC12345). В данном случае, представление номера клиента в Хабе будет алфавитно-цифровым и с максимальной длинной, чтобы хранить все номера клиента из разных функциональных областей бизнеса. В Хабе будет два вхождения: 12345 и AC12345, каждое будет иметь свой собственный источник данных: один из бухгалтерского учета и один из отдела контрактов. Очевидно, предпочтительнее было бы выполнить очистку и сопоставление этих номеров и интегрировать их в одну запись. Но это выходит за рамки данного документа. Первичный ключ Хаба всегда мигрирует из Хаба. Как только мы правильно идентифицируем бизнес посредством ключей (например, клиенты и счета), то могут быть построены сущности Связи.
3.2 Сущность Связь (Link)
Сущности Связи (или просто Связи) физическое представление связей многие ко многим третьей нормальной формы (3NF). Сущность Связь представляет отношения или транзакцию между двумя или более компонентами бизнеса (два или более бизнес ключа). Связь содержит следующие атрибуты:
- Суррогатный ключ (Surrogate Key) необязательный компонент, возможно смарт-ключ или порядковый номер. Используются только, если существует более двух Хабов связанных этой Связью, или если составной первичный ключ может привести к проблемам производительности.
- Ключи Хабов: от 1-го Хаба до N-го Хаба ключи Хабов мигрируют в сущность Связь, образуя составной ключ, и представляют взаимодействия и связи между Хабами.
- Временная отметка даты загрузки (Load Date Time Stamp), регистрирующая, когда связь/транзакция впервые была создана в хранилище.
- Источник данных (Record Source) регистрация исходной системы, используется для обратной трассировки (отслеживания) данных.
Это адаптация отношений многие ко многим третьей нормальной формы (3NF), решающая проблемы, связанные с масштабируемостью и гибкостью. Эта техника моделирования разработана для хранилищ данных, а не для OLTP систем. Имейте в виду, что некоторые из основополагающих правил для моделирования Data Vault будут перечислены в конце этого документа. С помощью только нескольких Хабов и Связей модель данных начнет описание потоков бизнеса (business flow). Следующий наш компонент должен объяснить: когда?, почему?, что?, где? и кто? создал, как сделки, так и, собственно, ключевые объекты. Например, недостаточно знать, что есть некоторый VIN у транспортного средства, или что есть водитель номер 5. Заказчик хочет знать, что именно представляет собой определенный VIN (например, синяя Тойота, пикап, 4WD и т.д.), и что водителя номер 5 зовут Джейн, и что это и есть водитель автомобиля с конкретным VIN.
3.3 Сущность Спутник (Satellite)
Сущности Спутники (или просто Спутники), являются контекстной (описательной) информацией ключа Хаба. Описание подвергается изменениям с течением времени, и поэтому структура Спутников должна быть способна хранить новые или измененные детальные данные. Значение VIN не должно меняться, но если ремонтная бригада, восстанавливая Тойоту, уберет верх и добавит трубчатый каркас (ролл-бар), машина не будет больше пикапом. Что делать, если Джейн продаст машину, кому-то еще, скажем, водителю под номером 6? Спутник состоит из следующих обязательных атрибутов:
- Первичный ключ Спутника: Первичный ключ Хаба или первичный ключ Связи мигрирует в Спутник из Хаба или Связи.
- Первичный ключ Спутника: Временная отметка даты загрузки (Load Date Time Stamp) регистрация, когда информация контекстная стала доступна в хранилище (всегда вставляется новая строка).
- Первичный ключ Спутника (необязательное поле): Последовательный (sequence) суррогатный номер используется для Спутников, которые имеют несколько значений (например, адрес выставление счетов и домашний адрес); или номер позиции строки, используется для поддержки подгрупп и порядка.
- Источник данных (Record Source) регистрация исходной системы, используется для обратной трассировки (отслеживания) данных.
Спутник наиболее близок медленноменяющимся измерениям 2-го Типа в определении Ральфа Кимбалла. Он хранит изменения на детальном уровне, а его функция заключается в обеспечении описательного контекста экземплярам Хаба или Связи. Например, факт, что VIN 1234567 представлял собой синий грузовик Тойота вчера, а сегодня это красный грузовик Тойота (перекрасили). Цвет может храниться в Спутнике автомобиля. Проектирование Спутников должно основываться на математических принципах сокращения избыточности данных и на скорости изменения данных. Например, если автомобиль арендуется, то дата доступности / аренды может меняться ежедневно, что гораздо чаще, чем скорость изменения цвета, шин или владельца. Проблема, решаемая Спутником, определяется следующим образом:
Автомобильное измерение может содержать более 160-ти атрибутов. Если используется 2-ой тип размерности, то при изменении цвета или замене шин, все 160 с лишним атрибутов должны копироваться в новую строку. Почему данные копируются, если остальная часть атрибутов меняется медленнее? При использовании измерений 1-го Типа или 3-го Типа можно частично или полностью потерять историю изменений. В таком случае проектировщик данных должен построить как минимум два Спутника: один с датами наличия автомобиля, второй, описывающий техническое обслуживание / комплектующие элементы. Если первый день арендует автомобиль клиент Дэн, а второй день Джейн, то сущности Связи отвечают за представление этих отношений. Проектировщик данных может добавить к Связи один или несколько Спутников, которые представляют даты аренды (от / до), состояние транспортного средства и замечания со стороны арендатора.
3.4 Создание Data Vault
Модель Data Vault должна строиться следующим образом:
- Смоделируйте Хабы. Для этого требуется понимать основные бизнес сущности (бизнес ключи) и как они используются в выбранной области.
- Смоделируйте Связи. Выявление возможных отношений между ключами требует формулировки, как бизнес работает сегодня в контексте каждого бизнес ключа.
- Смоделируйте Спутники. Обеспечение контекста, как каждой бизнес сущности (бизнес ключу), так и транзакциям/сделкам (Связи), соединяющим Хабы вместе. С этого начинается проявляться полная картина о бизнесе.
- Смоделируйте point-in-time таблицы. Это производные Спутников, структура и определение которых выходят за рамки этого документа (из-за ограничений по объему).
Существуют методы, для представления внешних источников, таких как плоские файлы, Excel и пользовательские файлы с разделителями — из-за нехватки времени и объема, эти вопросы не будут здесь обсуждаться. Все структуры и методы моделирования применяются независимо от типа источника.
Ссылочные правила для Data Vault:
- Ключи Хабов не могут мигрировать в другие Хабы (никаких Хабов подобных родитель/потомок не должно быть). Моделирование в такой манере нарушает гибкость и расширяемость техники моделирования Data Vault.
- Хабы должны быть связаны с помощью сущностей типа Связь.
- С помощью Связей может быть связано более двух Хабов.
- Сущности Связи могут быть связаны с другими сущностями типа Связи.
- Связи должны иметь, по крайней мере, два связанных с ними Хаба.
- Суррогатные ключи могут быть использованы в Хабах и Связях.
- Суррогатные ключи не могут быть использованы в Спутниках.
- Ключи Хаба всегда мигрируют наружу.
- Бизнес-ключи Хаба никогда не меняются, первичные ключи Хабов никогда не меняются.
- Спутники могут быть связаны как с Хабами, так и со Связями.
- Спутники всегда содержать либо временную отметку даты загрузки (Load Date Time Stamp), или числовой внешний ключ, ссылающийся на автономную таблицу, содержащую последовательность временных отметок загрузки.
- Могут быть использованы автономные таблицы, такие как календари, время, коды и описания.
- Сущности Связи (Links) могут иметь суррогатный ключ.
- Если Хаб имеет два или более Спутника, point-in-time таблица может быть создана для удобства операций соединения (join).
- Спутники фиксируют только изменения, дублирования строк не должно быть.
- Данные распределяются по структуре Спутников, основываясь на: 1) типе информации, 2) темпах изменения.
Эти простые компоненты Хаб (Hub), Связь (Link) и Спутник (Satellite) в совокупности образуют Data Vault. Хранилища Data Vault могут быть как малыми, с одним Хабом и с одним Спутником, так и настолько большими насколько требуют рамки применения. В последствии рамки всегда могут быть изменены, и ни масштабируемость, ни степень детализации информации не являются проблемой. Проектировщик данных может конвертировать отдельные компоненты существующей модели хранилища данных в архитектуру Data Vault только один раз. Потому что эти изменения обособят Хабы и Спутники. Связи представляют бизнес (как взаимодействие функциональных областей). Таким образом, Связи могут быть с ограниченным периодом действия, пересмотрены, перестроены и так далее.
4.0 Решение архитектурных недостатков хранилищ данных
3NF и схема Звезда, когда они используются для хранилищ данных предприятия, могут причинять бизнесу боль, потому что они не были изначально предназначены для целей хранилищ. Есть проблемы, связанные с масштабируемостью, гибкостью и степенью детализации данных, интеграцией и объемом. Объем информации, которую хранилища обязаны хранить сегодня, увеличивается по экспоненте каждый год. Приложения CRM, SCM, ERP и все другие большие системы приводят к увеличению объемов информации в хранилищах. Существующие модели данных, основанные на 3NF или схеме Звезда, оказывается, трудно изменять, поддерживать и анализировать, не говоря уже о резервном копировании и восстановлении.
В ранее приведенном примере мы реализовали хранилище Data Vault, состоящее из единственного Хаба и нескольких Спутников и ограниченное рамками хранения истории о транспортных средствах и соответствующих им атрибутах. Если год спустя бизнес захочет видеть в хранилище контракты по этим транспортным средствам, то необходимые Хабы и Связи могут быть легко добавлены. Не беспокойтесь о степени детализации. Этот тип модели расширяем верх и вширь (реализация снизу вверх, проектирование сверху вниз). Конечный результат всегда строго фундаментирован и может создаваться итерационным подходом к разработке.
Другой пример сильные возможности сущности Связь. Предположим, что сегодня компания, продающая продукцию, имеет Хаб Продукты, Хаб Счет и Связь между ними. Затем компания решает продавать услуги. Модель данных позволяет ввести новый Хаб Услуги, заполнить дату окончания в продуктовые Связи и начать новую Связь между услугами и счетами. Никакие данные не потеряны, и все данные, накопленные в течение долгого времени сохранены и отражают изменения бизнеса. Это лишь одна из многочисленных возможностей для обработки подобной ситуации.
Большой объем данных приводит к проблемам с запросами, особенно это касается схем Звезда, но в меньшей степени и 3NF. Нарушается производительность запросов при больших объемах информации в согласованных измерениях и согласованных таблицах фактов. Часто требуется делать партиционирование и непрерывно переделывать структуры, чтобы предоставить дополнительную степень детализации бизнес пользователям. Это обеспечивает кошмар обслуживания и управления. Перезагрузка постоянно меняющихся звезд является трудной задачей не говоря уже о попытке выполнить это с большим объемом данных (свыше 1 Терабайт, например). Data Vault уходит корнями в математические основы нормализованной модели данных. Сокращения избыточности и учет темпов изменения наборов данных способствует повышению производительности и простоте в управлении. Архитектура Data Vault не ограничивается применением какой-либо одной платформы. Архитектура так же позволяет использовать распределенный взаимосвязанный набор информации.
Хранилищам данных часто приходится дело с утверждением: То, что я (пользователь) дам Вам это никогда не приходит из исходных систем. И они предоставляют крупноформатную таблицу со своей ежедневно поддерживаемой интерпретацией информации. Другими словами: Я (заказчик) хочу видеть все номера VIN, которые начинаются с X, сгруппированными под названием BIG TRUCKS (БОЛЬШИЕ ГРУЗОВИКИ). В Data Vault предусмотрена такая возможность с помощью Набора Пользовательских Группировок (User Grouping Set). Это еще один Хаб (с названием Big Trucks) со Спутником, описывающим номера VIN, группируемые под этим лейблом, и Связь с номерами VIN. Таким образом, сохранены оригинальные данные из исходной системы, в то же время можно получить информацию в манере, соответствующей пользовательским потребностям. Когда все будет сказано и сделано, хранилище данных является успешным, так как оно отвечает потребностям пользователей.
5.0 Основы архитектуры Data Vault
Архитектура уходит корнями в математику сокращения избыточности. Спутники предназначены только для хранения дельты или изменившейся информации. Если один из спутников начинает быстро расти, очень легко создать два новых спутника и запустить процесс, разделяющий дельту; процесс, который будет разделять информацию в два новых спутника, каждый процесс выполняет другой дельта-процесс перед вставкой новых строк. Этот процесс может сократить процент дублирования колоночных данных до минимума. Это приравнивается к использованию меньшего объема хранения. Спутники по своей природе могут быть очень длинными, и в большинстве случаев узкими (имеют не много столбцов). Для сравнения, измерения 2-го типа могут реплицировать данные во многих столбцах, делать копии информации снова и снова, а также создавая новые ключи.
Хабы хранят по одному экземпляру бизнес ключа. Бизнес ключи, как правило, имеют очень низкую склонность к изменениям. Поэтому суррогатные ключи отображаются один к одному на бизнес ключи (если используются суррогаты) и никогда не меняются. Первичный ключ Хаба (независимо от типа — бизнес или суррогатный) является единственным компонентом информации, реплицированным между Спутниками и Связями. Поэтому Спутники всегда привязываются непосредственно к бизнес ключу. Таким образом, Спутникам отводится роль описывать бизнес ключи на наиболее доступном детальном уровне. Это обеспечивает основу для развития контекста, описывающего бизнес.
Другим уникальным результатом Data Vault является возможность динамически представлять отношения. Отношения создаются структурой Связей сразу же как ассоциированные бизнес ключи поступают из источника данных. Эта связь существует, пока они не датированы датой окончания (в Спутнике), либо не удалены из набора данных полностью. Тот факт, что эти отношения представлены таким образом, открывает новые возможности в области динамического создания отношений. Если в результате интеллектуального анализа данных обнаружены новые отношения между двумя хабами (или их контекстом), то новые Связи могут быть сформированы автоматически.
Кроме того, структуры Связи и информация могут быть отмечены конечной датой или удалены, когда они утратят свою актуальность. Например: сегодня компания продает продукцию, и имеет таблицу связи между продуктами и счетами-фактурами. Завтра, они начинают продавать услуги. Это очень просто реализуется, путем создания Хаба Услуги и связи между счетами и услугами, затем все отношения между товарами и счетами-фактурами датируются как оконченные. В этом примере, процесс изменения модели данных можно начать исследовать с программной точки зрения. Если это автоматизировать, то можно будет динамически изменять и адаптировать структуру хранилища данных, чтобы удовлетворить потребности деловых пользователей.
Темпы изменения и сокращение избыточности наряду с гибкостью потенциально неограниченных динамических изменений отношений формируют мощную основу. Эти слагаемые открывают двери применению структур Data Vault для множества различных целей.
6.0 Возможные применения Data Vault
Благодаря фундаментальности может быть рассмотрено много различных приложений Data Vault. Некоторые из них уже разработке. Небольшой перечень этих возможностей ниже:
Источник: