










Разработка простейшего логического анализатора на базе комплекса Redd
Содержание
- Определяем функциональность анализатора
- Методика сжатия потока
- Производительность анализатора
- Разработка головы анализатора
- Упаковка головы в компонент для процессорной системы
- Проектируем процессорную систему
- Финал работ
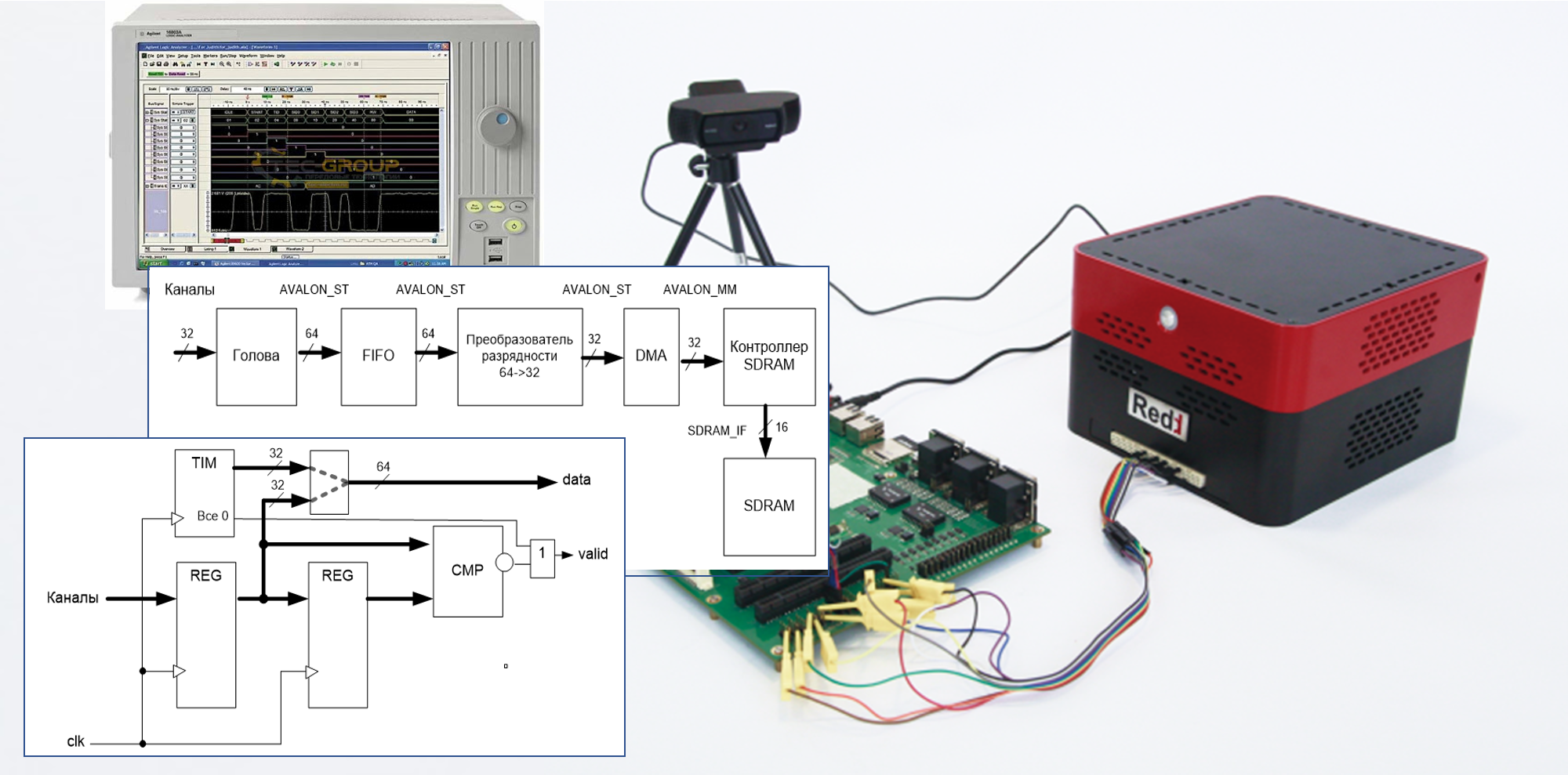
В прошлой статье цикла мы потренировались сохранять данные из потокового интерфейса в память средствами DMA. Пришла пора сделать какую-то полезную поделку, используя полученные навыки. Очень полезная при удалённой отладке вещь — анализатор. Вообще, при работе с комплексом скорее нужны специализированные шинные анализаторы, но начинать лучше с чего-то попроще. Поэтому сейчас мы сделаем простейший логический анализатор на 32 канала. Понятно, что он будет совсем-совсем примитивным, но зато мы сделаем его своими руками. У кого ещё нет комплекса Redd, могут повторить опыт, используя любую макетную плату с ПЛИС фирмы Altera (Intel) и микросхемой ОЗУ. Итак, приступаем.
Определяем функциональность анализатора
На самом деле, самый-самый простейший анализатор мы сделали ещё в прошлый раз. Напомню, как выглядит шина AVALON_ST, скопировав рисунок из старой статьи:
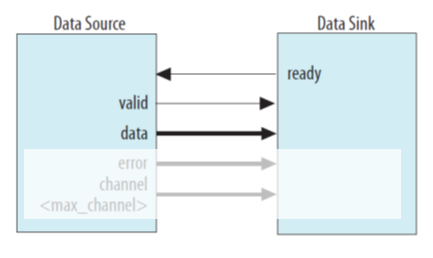
То есть пробросили внешние линии на шину data, взвели сигнал valid, и началось запоминание по принципу «отсюда и до обеда». Ну, то есть, пока память не закончится. Так работал мой осциллограф смешанных сигналов RIGOL, так работал логический анализатор HANTEK. Если для осциллографа смешанных сигналов по-другому нельзя, ведь аналоговый сигнал всё время изменяется, а он сохраняется вместе с цифрой, то для логического анализатора такой подход – более, чем странен. Зачем сохранять данные без сжатия? В далёком 2007-м году добыл я китайский анализатор LA5034. Он был настолько китайским, что даже программа к нему сначала не имела английского интерфейса! Так вот, даже он уже не расходовал память на сохранение одних и тех же данных. Имея всего несколько килобайт ОЗУ (встроенного в ПЛИС), он позволял делать намного больше, чем дурацкий HANTEK с многомегабайтными микросхемами памяти.
В общем, нам сейчас предстоит для этой основы сделать систему сжатия данных. А вот кольцевой буфер, блок триггера и блок фильтрации потока мы сегодня делать не будем – всё-таки статья должна содержать что-то простенькое. Тем более, что я не описываю какую-то готовую разработку, я проектирую анализатор чисто ради статьи. Потом он, конечно, пойдёт в набор примеров для комплекса, но всё равно, много времени на разработку мне никто не даст. Так что сжатие – это святое, а триггеры и фильтрация потока – это каждый добавит сам, если оно ему понадобится.
Методика сжатия потока
Я выбрал самую простейшую методику сжатия. Линия задержки и компаратор прямого и задержанного на один такт сигнала.
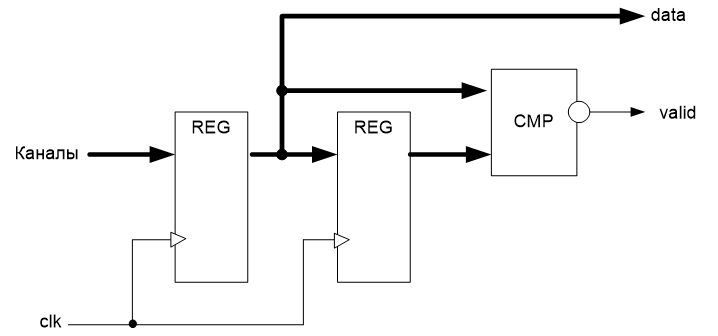
Первый регистр на схеме выполняет чрезвычайно важную функцию. Нельзя работать с недискретизированными данными! Много лет назад я на этом обжёгся. У меня в проекте автомат переходил из одного состояния в другое. Всё бы ничего, но на графе переходов не было такой стрелки. В чём же дело? А я анализировал как раз «сырые», а не дискретизированные данные. В результате, они могли изменить своё состояние в любой момент. Как известно, внутри ПЛИС у линий GCK скорость распространения более-менее единая, у остальных же линий – совершенно произвольная. А состояние автомата задавалось в двоичном виде. То есть, для его хранения использовалось несколько битов, хранящихся в нескольких триггерах. В отличие от процессора, новое содержимое, которое защёлкнется в каждый бит, вычисляется независимо. И время прохождения сигнала в процессе этих вычислений от входа до триггера – тоже для каждого бита своё.
И вот. Надо нам, скажем, перейти из состояния 0000 в зависимости от условий, или в 0001 или в 0110. И вот условие перехода изменилось очень близко к тактовому импульсу. Давайте я обозначу красными те биты, до которых данные успеют добежать, поэтому они примут новые значения для перехода в 0001, а синими – те, до которых не успеют, и они примут значение для перехода в 0110. Итак: 0 0 0 0 .

В итоге, получаем состояние 0011. А на графе такого перехода не было! Кодирование методом OneHot не решит проблему, просто она станет очевидной (а так – пока я отловил врага, пока понял, кто виноват – 4 дня убил, ведь проявлялась беда очень редко, да и сначала я грешил на неверную реализацию логики).
Чтобы избежать этого, дискретизируем всё и вся! Что бы там ни защёлкнулось на входе, на выходе оно будет иметь стабильное состояние на протяжении такта. Поэтому на вход компаратора попадут уже стабильные данные!
Ну, а второй регистр будет иметь на выходе данные, которые пришли на прошлом такте… Если прошлое и текущее значения не совпадают — надо новое сохранить, для чего взводим сигнал valid.
У такой системы сжатия только один недостаток, но он делает её в таком виде совершенно неприемлемой. Мы не знаем, как долго держалось каждое стабильное состояние. Чтобы устранить данную проблему, добавим таймер. Если сейчас данные 32 бита, то имеет смысл добавить ещё 32-битный таймер, так как суммарная шина должна удваиваться, а после 32 идёт разрядность 64. Просто будем защёлкивать натикавшие показания. Зная значение таймера для прошлой и текущей записи, мы всегда поймём, как долго держалось прошлое значение. Правда, таймер имеет свойство переполняться. На частоте 100 МГц он переполнится через 42.9 секунды. Но ничто не мешает нам при нулевом значении таймера также произвести защёлкивание данных. Накладные расходы памяти будут не так велики, а программа догадается, что произошло переполнение и надо начать отмерять значения с начала. В итоге, получаем такую блок-схему:

Производительность анализатора
64-битная шина данных при 16-битной микросхеме SDRAM – это не совсем хорошо. Допустим, мы тактируем ОЗУшку частотой 100 Мгц. Тогда, чисто теоретически, мы не можем использовать частоту дискретизации выше 25 МГц, ведь фактически каждое 64-битное слово будет уходить в ОЗУ в виде четырёх 16-битных слов. А практически, с поправкой на подачу команд микросхеме ОЗУ и циклы регенерации, предельная рабочая частота будет и того меньше. Может, даже 20 МГц.
Что на это можно сказать? Да, при разработке комплекса Redd не стояло задачи сделать супер производительный анализатор. Давайте взглянем на фирменные анализаторы, имеющиеся у меня под рукой. Вот простенький 16-битный. В нём стоит целых две ОЗУшины. Все ножки ПЛИС обслуживают каналы и ОЗУ. Ну, ещё на стык с USB уходят. А в Redd они ещё и для других целей используются.

Вот тот самый многострадальный абсолютно бесполезный HANTEK. Сжатия нет, но тоже две ОЗУшины. Причём, насколько я помню – DDR. В своё время, неплохо его изучил: несколько лет назад хотел сделать «прошивку» со сжатием, даже выпросил у производителя UCF-файл, но так и не освоил работу с ОЗУ у Xilinx. Но с тех пор я мог подзабыть детали схемы.

А вот так изнутри выглядит туловище анализатора LeCroy через отверстие под установку головы:

Там целых четыре модуля памяти с кучей микросхем каждый. Мне не хочется его сейчас вскрывать, но когда я отчищал его от пыли, сильно проникся внешним видом той ПЛИС, которая стоит внутри. Столько модулей памяти в параллель обслуживать – много ножек и ресурсов ПЛИСине требуется. И цена такого анализатора (разумеется, нового, а не с eBay) – десятки тысяч долларов. Насколько я помню, даже больше полусотни тысяч.
В целом, если кому-то позарез нужна производительность, он может или приобрести макетную плату с 32-битной ОЗУ, или разработать свою, установив туда две 32-битные ОЗУшины. Или даже модули DIMM. Но это уже будет BGA ПЛИС, у неё будет уже другая цена, и всё (включая класс печатной платы) другое. А теория – будет та же, что и сейчас, просто надо будет выкинуть преобразователь разрядности шины. Так что продолжаем рассуждения.
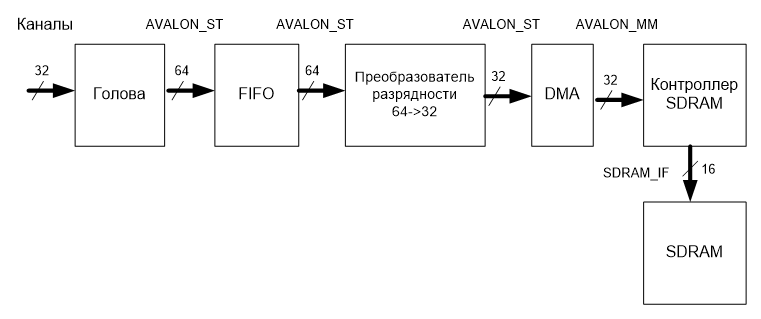
Вообще, на самом деле, и у нас всё не так плохо. Если данные идут небольшими пачками, то необходимо и достаточно установить блок FIFO. Пришла пачка – она попала в очередь. Дальше – на входе тишина, а данные из очереди постепенно уходят в ОЗУ. Таким образом, мгновенная производительность анализатора будет 100 МГц… Но в целом – всё будет хорошо при условии, что не переполняется FIFO. Именно поэтому я сделал целую статью, которая помогает оставить как можно больше памяти для нужд этого самого блока FIFO. Самое главное – блок должен быть установлен там, где шина данных ещё 64-битная. Итого, получаем блок-схему анализатора:
Разработка головы анализатора
Ну что ж, приступаем к разработке головы. Я как-то привык к терминологии мощных шинных анализаторов, у которых имеется универсальное туловище, а уже к нему подключаются проблемно ориентированные головы. Поэтому и у нас будет туловище и голова. Для реализации выбранной схемы не нужно даже делать никаких автоматов.
Интерфейс модуля будет таким:
Вот так мы реализуем процесс, который защёлкивает данные в регистрах и увеличивает счётчик:
Первое условие записи:
Второе условие записи:
Результирующее условие записи:
Ну, и из опытов ясно, что байты на шине надо немного перекрутить:
Собственно, всё. Давайте для полноты картины я вставлю полный текст модуля в слитном варианте.
Упаковка головы в компонент для процессорной системы
Как-то зловеще звучит заголовок… Но как бы там ни было, а упаковать всё в компонент нам надо. Мы тренировались делать подобное в этой статье.
У меня получилась шина AVALON_ST, штатные линии тактирования и сброса, и… Но сначала рисунок с типовыми вещами:

Из нетиповых: для будущей задумки линии conduit пришлось дать осознанное имя типу сигнала. Оно нам ещё пригодится.
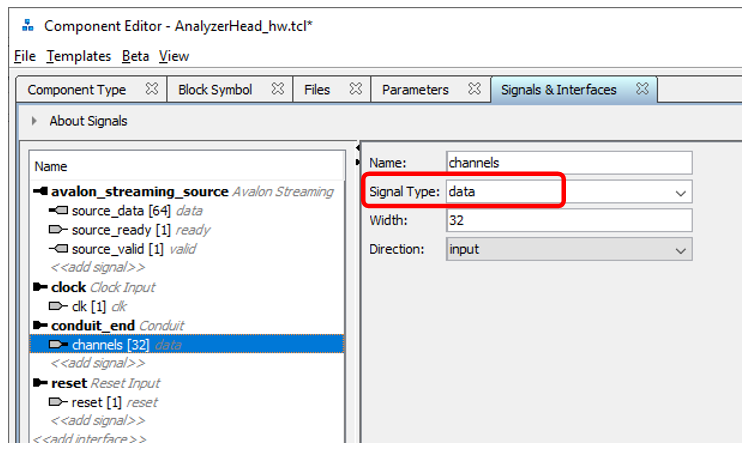
В остальном – вроде, всё понятно.
Проектируем процессорную систему
Как мы уже рассматривали в этой статье, мы не станем добавлять в систему процессорное ядро Nios II, а воспользуемся блоком Altera JTAG-to-Avalon-MM.
Работать с контроллером SDRAM мы учились в этой статье, а в этой разбирались, как при помощи блока PLL разогнать систему до 100 Мгц. Экспериментировали с FIFO и изменением ширины шины AVALON_ST при помощи блока AVALON_ST_ADAPTER мы в этой статье. Наконец, с DMA мы экспериментировали буквально в прошлой статье.
Пришла пора собрать все эти знания в едином проекте! Вот такая у меня получилась навёрнутая структурная схема.

Страшно? Ничуть. Давайте пройдёмся по ней сверху вниз. Сначала идёт блок тактирования и сброса. Как всегда, для комплекса Redd, чтобы не мучиться, физическую ножку Reset я не использую (я её всегда виртуальной делаю). Так удобнее для данной конкретной аппаратуры, хоть и не совсем правильно. Тактирование же идёт на блок PLL. Как его настраивать, мы уже подробно рассматривали раньше. Если я вставлю сюда массу скриншотов, то сильно перегружу статью. С выхода c0 мы берём тактовый сигнал для всей нашей системы, а выход c1 – экспортируем и подключаем к тактовому входу микросхемы SDRAM.
Master0 – это тот самый компонент Altera JTAG-to-Avalon-MM, через который мы будем достукиваться до шины AVALON_MM. Он в настройках не нуждается. Доступ к шине нам нужен, чтобы управлять блоком DMA и чтобы считывать содержимое SDRAM с накопленными результатами.
Дальше идёт наш компонент «Голова». А уже из неё растекается поток через цепочку шин AVALON_ST. Сначала он затекает в блок FIFO. Это – первый блок, настройки которого стоит показать особо:
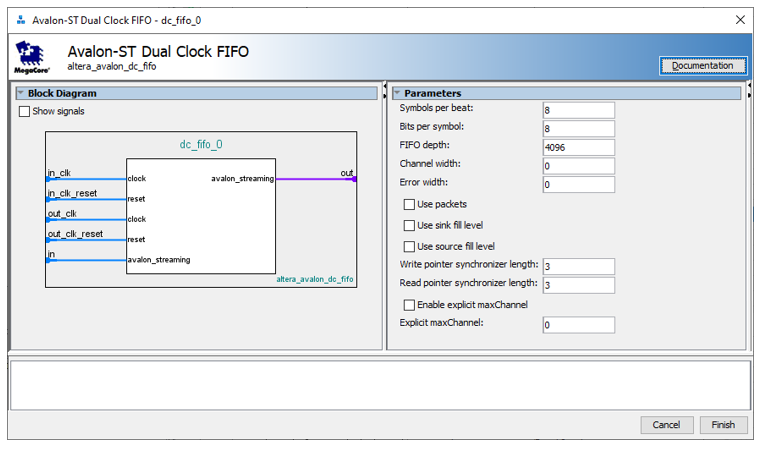
8 символов на слово, каждый символ 8 бит. Итого 8*8=64 бита. Ёмкость – 4 килослова. Все остальные вещи протокола AVALON_ST отключены. Двойное тактирование сделано для того, чтобы в будущем голова могла работать на частоте, отличной от частоты работы туловища. Это нам пригодится, когда мы будем делать шинный анализатор USB.
Дальше данные перетекают в преобразователь разрядности. Вот его настройки:
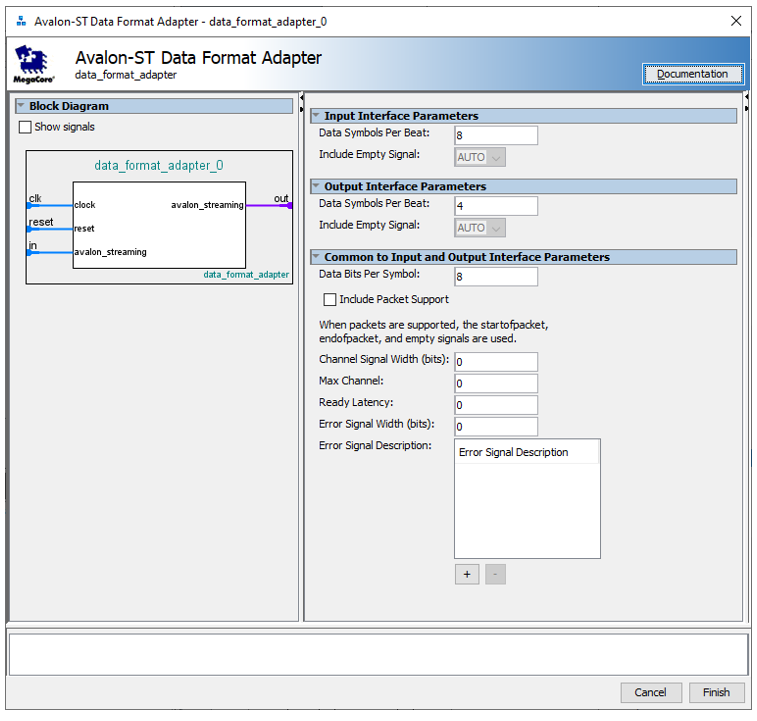
Собственно, 8 символов на слово на входе, 4 символа на слово – на выходе. 8 бит на символ. Тоже всё просто. Наконец, поток входит в блок DMA. Ему я только типы шин и максимальную длину передачи поправил, да выставил режим доступа только в режиме полного слова, чтобы поднять Fmax. По уму, такой огромный объём памяти дескрипторов не нужен (хотя, нутром чую, что через них мы можем реализовать кольцевой буфер для анализатора). Размер входного FIFO тоже можно уменьшить до минимума, ведь у нас есть FIFO до этого блока. Но, честно говоря, работа над статьёй и так уже затянулась, так что оставим эту оптимизацию для читателей в качестве самостоятельной работы.
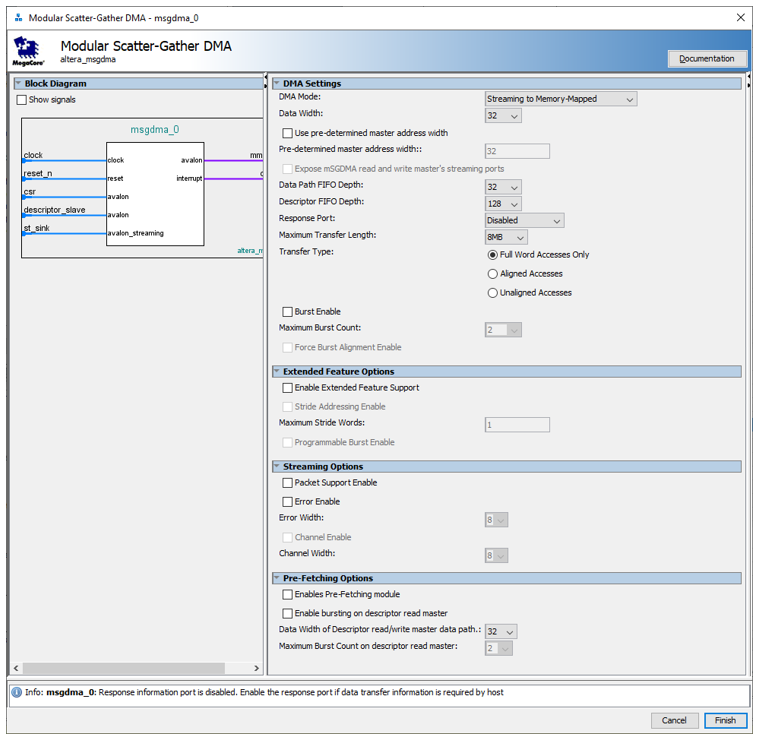
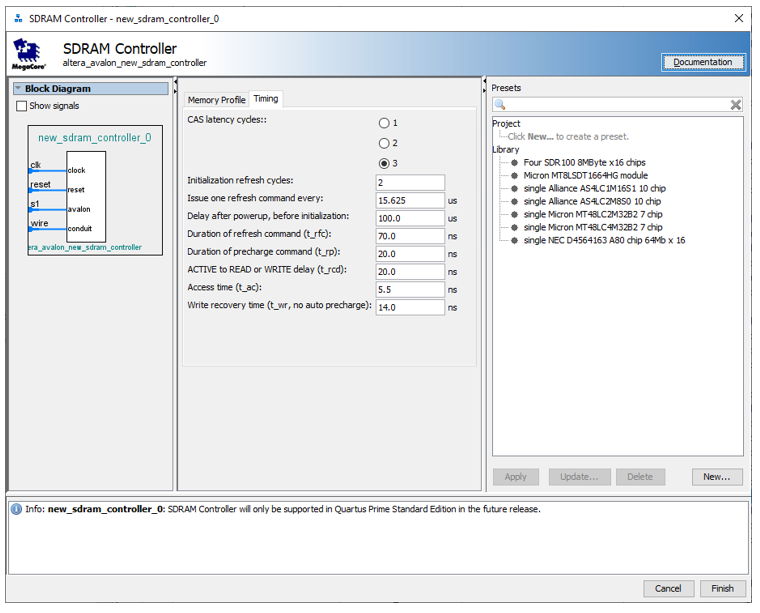
Всё. Потоковая часть завершена. Дальше данные попадают в контроллер SDRAM. Напомню его настройки

Из функциональной части – всё. Но кто следит за рассказом не по диагонали, а внимательно, наверное, заметил ещё один странный блок DataGen_0. Что это такое? Мы раньше такого не применяли!
Дело в том, что мне же как-то надо проверить работу головы. А это надо все 32 линии назначить на какие-то ножки ПЛИС, подключить к ним какой-то источник… А все должны будут поверить мне на слово, что я это сделал. И потом думать, как это повторить у себя. Зачем? Давайте добавим тестовый генератор данных и подключим его не проводами, а через трассировочные ресурсы ПЛИС. Я сделал самый простой счётчик, который увеличивает своё значение в случайные моменты времени. В качестве генератора случайных чисел я взял 32-разрядную M-последовательность, а увеличиваю счётчик, когда в младших восьми битах появляется константа 0x12. Вот такой получился SystemVerilog код, реализующий эту функциональность (обратите внимание, что я по-прежнему не использую сигнал reset, хотя, здесь бы он пригодился):
В настройках компонента самая важная деталь – это имя параметра Signal Type у conduit шины. Он должен быть таким же, какой я заполнил у соответствующего параметра головы. В остальном – всё просто, здесь же нет никаких специальных шин, только conduit…
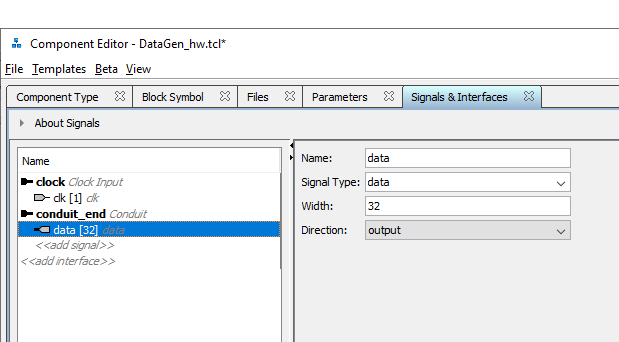
Соединяем соответствующие линии (это единственное соединение на структурной схеме выше, которое я не стал подсвечивать каким-либо цветом), получаем то, что нужно.
Финал работ
Делаем линию reset виртуальной. Всем остальным ножкам я предпочёл сделать назначение не в GUI, а скопировал фрагмент файла *.qsf из проекта, сделанного в самой первой статье.
Источник: